Biblical Studies
Biblical Studies
Anselm Project Bible v2.0 Released
Version 2.0 of the Anselm Project Bible introduces a blind-translator pipeline, Grok-powered generation, name standardization, and literal yet polished English.
Version 2.0 of the Anselm Project Bible is a complete rewrite. New translation pipeline, new AI system, new proper name handling, everything.
I completed it in three days.
This is the last major Bible update for a while. I'm confident in what's here.
The Blind Translator Problem
Version 1 had a fundamental issue I couldn't fully solve - the AI knew it was translating the Bible. Even when I told it not to rely on tradition, it would recognize biblical patterns and default to familiar translations instead of actually translating the Hebrew or Greek I gave it.
Mark 1:1 was the classic example. I'd feed it Greek text without "the Son of God" and it would add that phrase anyway because that's how Mark 1:1 traditionally reads. The AI was cheating.
Version 2.0 fixes this with what I call the "blind translator" approach. The translation AI has no idea it's working with biblical text. I removed every reference to Scripture, the Bible, theology, anything religious from the translation prompts. The AI just sees ancient language text that needs translating into formal English.
The result is a translation that's more literal and in many places clunkier than version 1. But it's significantly more honest. The clunkiness is actually proof the system is working - when the AI isn't defaulting to familiar traditional renderings, you get more word-for-word accuracy even if it sounds awkward in English.
It can't cheat if it doesn't know what game it's playing.
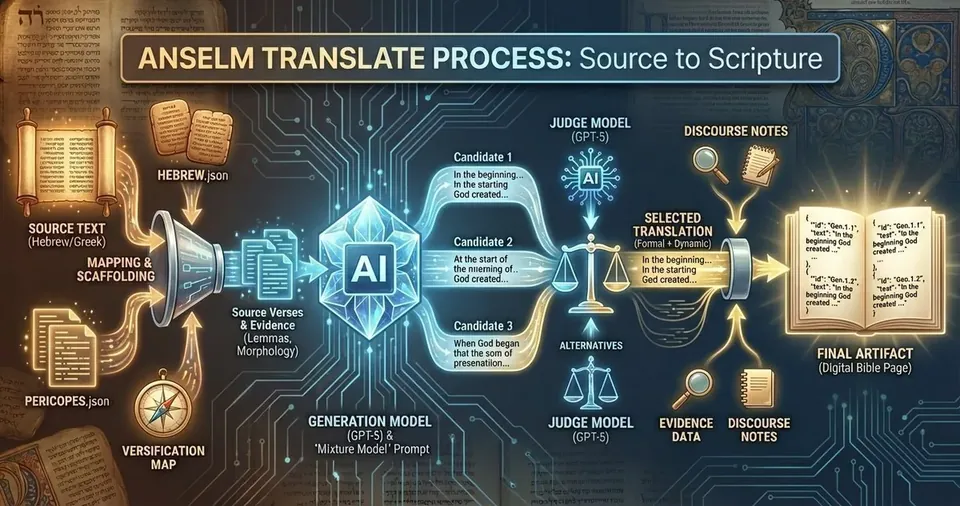
Four Steps Instead of Three Candidates
Version 1 generated three translation candidates and had a judge pick the best one. Version 2.0 uses a four-step pipeline that's more sophisticated and produces better results.
Step 1: Generate - The system generates five translation candidates for each pericope. Not three, five. More options means better final selection. Each candidate uses the same mixture model philosophy but with slightly different generation parameters.
Step 2: Judge and Extract - A separate judge AI evaluates all five candidates and selects the single best one. But it does more than just pick a winner. During this step, the judge also extracts every proper name from the selected translation. This is critical for the next step.
Step 3: Standardize Names - The system takes all the proper names extracted in step 2 and standardizes them to match English Bible conventions. No more "Beth-sheba" versus "Bathsheba" inconsistencies. The divine name gets normalized to "The LORD" as English Bibles traditionally render it. Geographic names, personal names, everything gets standardized to match what English readers expect.
Step 4: Polish Syntax - The final step takes the standardized translation and polishes the syntax for natural readability. This isn't changing meaning or adding interpretation. It's smoothing out awkward constructions that might have survived the earlier steps while maintaining the formal, literary tone.
Each step saves its output incrementally. If something crashes at step 3, you don't lose the work from steps 1 and 2. This was essential for processing 2,022 pericopes without losing data.
Switching to Grok
Version 1 used OpenAI's GPT-5 for translation and GPT-5-mini for judging. Version 2.0 switches to xAI's Grok 4.1 for everything. Specifically, Grok fast-non-reasoning for the translation generation and Grok fast-reasoning for the judge step.
The main reason for the switch: cost. Grok is significantly cheaper than GPT-5, which meant I could run the full-power 4.1 model constantly without worrying about token costs. Version 1 had to balance power versus expense. Version 2.0 runs full throttle all the time.
Grok also returns data fast. The speed combined with lower costs meant I could process the entire Bible in three days. The raw speed of Grok's responses was the real advantage.
Structured output handling was actually more challenging with Grok than with GPT. I had to work around some quirks. But the speed and cost benefits outweighed the structured output difficulties. I moved to Pydantic schemas for all outputs which helped enforce validation at the API level.
Proper Name Standardization
The new proper name handling is a major improvement. In version 1, I had inconsistent name rendering across pericopes. "Jehoshaphat" might show up as "Yehoshafat" in one passage and "Jehoshaphat" in another depending on how the AI felt that day.
Version 2.0 extracts names at the judge step and runs them through a standardization process. The system has a lookup table of biblical names with their conventional English spellings. When it encounters "Yeshayahu" in the Hebrew, it maps that to "Isaiah" in the final English output.
The divine name handling is explicit. All variations of the tetragrammaton render as "The LORD" following English Bible tradition. Elohim becomes "God," Adonai becomes "Lord," and so on. The standardization is automatic and consistent across all 31,102 verses.
This consistency also feeds into the biblical lexicon, which I'm repurposing to provide definitions for significant biblical terms and words rather than just general biblical data. Over the next few days, I will be generating lexical data that should tie directly into the APB.
Decision Bots Architecture
The evidence-building system got completely refactored into modular decision bots. Each bot has a specific job and runs independently. The main bots are: MorphologiesBot, ProperNamesBot, KeywordConsistencyBot, and AmbiguityBot.
MorphologiesBot runs first because everything else depends on it. It generates the grammatical parsing for every Hebrew and Greek word - tense, voice, mood, case, number, gender, everything. This data feeds into every biblical report the system generates.
ProperNamesBot builds a comprehensive database of every person, place, and divine name in Scripture. KeywordConsistencyBot tracks how key theological terms get translated across different contexts. AmbiguityBot flags passages where the source text is genuinely unclear so the system can document translation choices.
The architecture is modular. You can run individual bots on specific books or chapters. You can add new bots without touching the core pipeline. Each bot saves its results to a separate JSON file in the decisions directory.
This modular approach makes debugging much easier. If morphology data looks wrong for Genesis chapter 3, I can re-run just the MorphologiesBot on Genesis 3 without regenerating the entire Bible.
Evidence System Improvements
The evidence compilation system now generates a single evidence.json file per book instead of scattering data across multiple files. Each evidence.json contains lemmas, morphology tags, and parallel passages for every verse in that book.
The morphology code format changed to match what the Bible reader expects. Version 1 used one format internally and had to convert on the fly. Version 2.0 standardizes on a single format from the beginning. Nouns are tagged as "NOUN,nom,sg,m" and verbs as "VERB,aor,act,ind,3,sg" with no conversion needed.
Parallel passages are integrated directly into the evidence structure. When you look up a verse in the Anselm Project Bible, you see three to five cross-references automatically. These aren't random - they're generated by a separate bot that analyzes thematic and textual connections across Scripture.
Structured Output Validation
One of the most important changes is how the system handles AI responses. Version 1 put JSON formatting instructions in the prompts and hoped the AI would comply. Sometimes it did, sometimes it didn't. Parsing errors were common.
Version 2.0 uses Pydantic schemas with the API's structured output feature. The system defines exactly what structure it expects and the API enforces that structure at the generation level. The AI literally cannot return malformed JSON because the API won't let it.
This eliminated an entire class of errors. No more "Failed to parse JSON response" messages. No more manual JSON cleanup. The structured output is guaranteed valid or the API returns an error that triggers a retry.
What This Means for You
The translation quality is significantly better. The blind translator approach produces more accurate renderings because the AI isn't defaulting to tradition. The four-step pipeline with proper name standardization means consistent terminology across all 66 books.
The evidence system improvements mean better morphology data, more reliable cross-references, and cleaner structured data for every verse. Reports generated from the APB now have access to richer linguistic information.
The Share Gallery already has reports generated from the new APB data. You can see the quality improvement in how passage reports handle Greek and Hebrew terms now. The lexicon integration is tighter because the underlying data structure is cleaner.
The Final Token Count
According to Grok's dashboard, version 2.0 used 341,514,131 total tokens. That breaks down to 189,864,769 cached prompt tokens, 45,897,784 completion tokens, and 105,751,578 prompt tokens.
The caching system helped significantly - nearly 190 million cached tokens meant the system wasn't re-processing the same prompts repeatedly. The entire translation completed in three days.
This Is It For A While
I'm happy with version 2.0. The architecture is solid, the translation is much more honest and reflects a committee better, and the evidence system is comprehensive. I don't plan major Bible updates for a while. There might be minor fixes if I find errors, but the core system is done.
The APB remains completely free with no account required. You can read the entire Bible, see all the morphology data, check cross-references, everything. That's not changing.
If you want to see what version 2.0 looks like in action, check out the Anselm Project Bible. Compare it to traditional translations. Look at the morphology tags. See how the cross-references work. This is what a complete ground-up rewrite produces.
God bless, everyone.